
1Department of Plant Science, Plant Genomics and Breeding Institute, and Research Institute of Agriculture and Life Sciences, College of Agriculture and Life Sciences, Seoul National University, Seoul 08826, Korea
2Department of Life Science, Chromosome Research Institute, Sahmyook University, Seoul 01795, Korea
3Joeun Seed, Goesan 28051, Korea
4Indonesian Industrial and Beverage Crops Research Institute, Sukabumi 43357, Indonesia
5Genomics Division, Department of Agricultural Bio-Resources, National Academy of Agricultural Science, Rural Development Administration, Jeonju 55365, Korea
6Phyzen Genomics Institute, Seongnam 13558, Korea
7Crop Biotechnology Institute/GreenBio Science and Technology, Seoul National University, Pyeongchang 25354, Korea
Copyright © 2016 The Korean Society of Breeding Science
This is an Open-Access article distributed under the terms of the Creative Commons Attribution Non-Commercial License (http://creativecommons.org/licenses/by-nc/4.0) which permits unrestricted non-commercial use, distribution, and reproduction in any medium, provided the original work is properly cited.
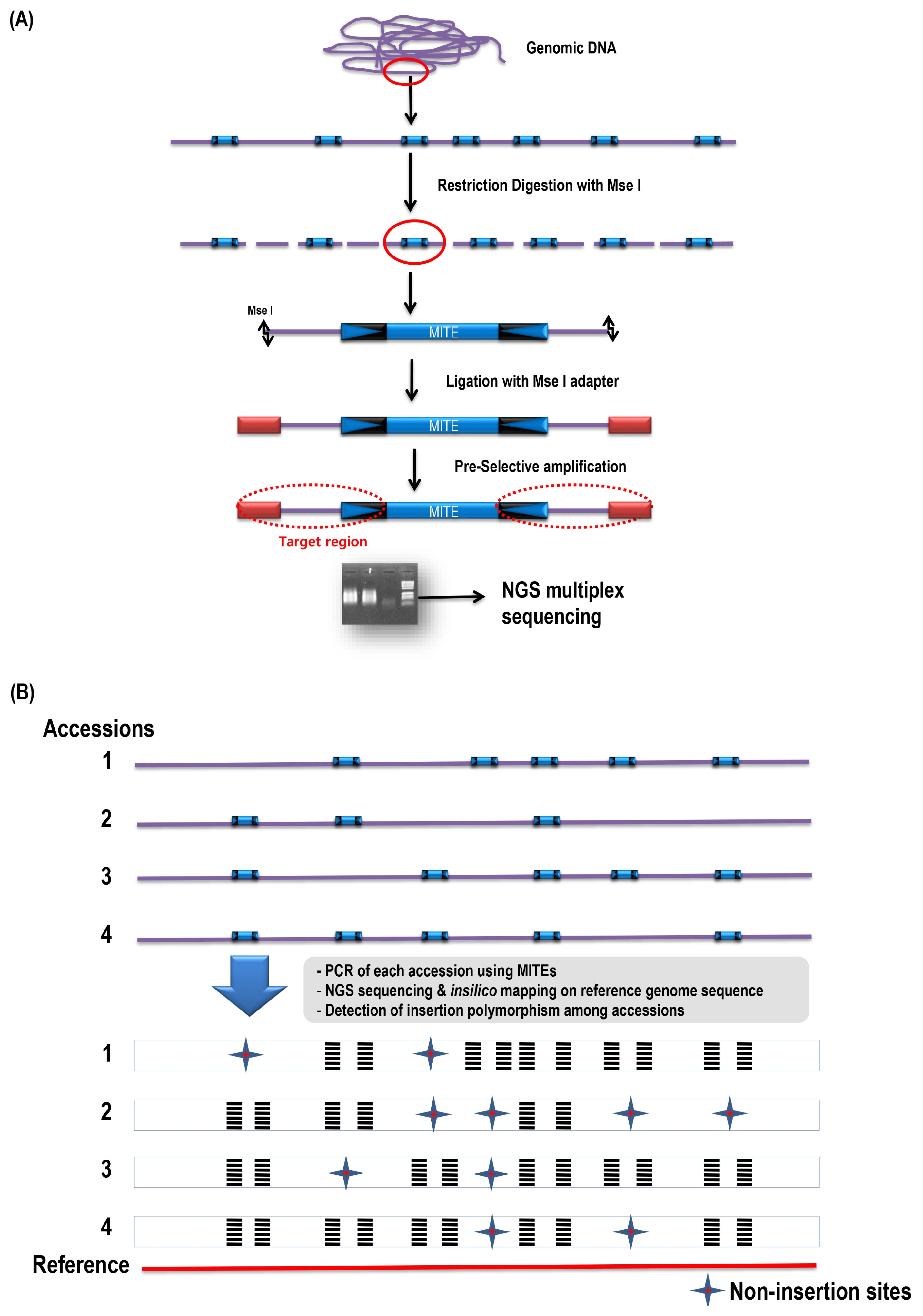

| No. | ID | Species | Accession no. | Reference |
|---|---|---|---|---|
| 1 | Br1 | Brassica rapa | ‘Chiifu’ (C) | (Wang et al. 2011) |
| 2 | Br2 | B. rapa | ‘Kenshin’ (K) | (Sampath et al. 2013) |
| 3 | Br3 | B. rapa | OC 1 | (Lee et al. 2014) |
| 4 | Br4 | B. rapa | OC 2 | (Lee et al. 2014) |
| 5 | Br5 | B. rapa | YE 1 | (Lee et al. 2014) |
| 6 | Br6 | B. rapa | YE 2 | (Lee et al. 2014) |
| 7 | Bo1 | Brassica oleracea | C1234 | (Lee et al. 2015) |
| 8 | Bo2 | B. oleracea | C1184 | (Lee et al. 2015) |
| 9 | Bo3 | B. oleracea | C1235 | (Lee et al. 2015) |
| 10 | Bo4 | B. oleracea | C1176 | (Lee et al. 2015) |
| Accession | Insertion sites based on in silico mapping | PCR validation | |||
|---|---|---|---|---|---|
|
|
|
||||
| Total | Accession specificz) | Success | IP-Bs2 among Br1, Br2 | IP-Bs2 among 10 accessions | |
| Br1 | 127 | 83 | 75 | 27 (36) | 59 (78) |
| Br2 | 60 | 16 | 15 | 7 (46) | 10 (66) |
| No. | Primer sequence | Product size (bp) | Temperature (°C) | Primer source | In silico specificity | PCR validation | Gel profilez) | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
|
|
|
|||||||||||||||||
| Forward (5′–3′) | Reverse (5′–3′) | Chr# | Start | End | Br1 | Br2 | Br3 | Br 4 | Br 5 | Br 6 | Bo1 | Bo2 | Bo3 | Bo4 | |||||
| 1 | TTGTTTGATCAGGGGAGCAT | CCAGGGTACCTATCCGCTTT | 858 | 58.45 | 1 | 21801279 | 21802374 | C | C | 1 | 2 | - | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
| 2 | TTGCAGATTTGATGTTGTGAA | GCGCGGGTTATTACCTAGTG | 713 | 57 | 2 | 23504716 | 23506305 | C | C | 1 | 2 | 3 | 1 | 3 | 1 | 1 | 1 | 1 | 1 |
| 3 | CTACCGCCAAGTTCAAGCA | TAAGGGACCCCAAAGCATAA | 773 | 56.85 | 3 | 742954 | 744043 | C | C | 1 | 2 | 3 | 3 | 3 | 3 | 1 | 1 | 1 | 1 |
| 4 | TTGAGCCTAGTCCGAGCAAT | CTCATCTCCAAACCCCATTC | 749 | 58.4 | 3 | 10933621 | 10934710 | C | C | 1 | 2 | 1 | 3 | 3 | 1 | 1 | 1 | 1 | 1 |
| 5 | ACCGTGGTGAGGTAAAAGGA | TGTTCTTTGCCTTGGAACCT | 751 | 57.4 | 3 | 18816045 | 18817634 | C | C | 1 | 2 | 1 | 3 | 3 | 1 | 2 | 2 | 2 | 2 |
| 6 | TGCAGATCTCTTTGCTCATCA | CTGTTCTCTGCGATGCTCAC | 746 | 58.95 | 3 | 20935930 | 20936992 | C | C | 1 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
| 7 | GCATCTCTGAGCTGGTTTCC | GTCCTCGTTGACGGAGAAAG | 976 | 60.5 | 3 | 17138648 | 17140237 | C | C | 1 | 2 | - | - | - | - | - | - | - | - |
| 8 | GCAAATTATGCACAATCTTACAA | TGGATATATGATGCTGTCAAAAA | 751 | 55.7 | 3 | 23886171 | 23887233 | C | C | 1 | 2 | - | 2 | 1 | 2 | - | - | - | - |
| 9 | GGAATCGAATGGGATCAAAA | TCTAAAAACGCTGGCTCCAT | 886 | 55.35 | 5 | 11493271 | 11494360 | C | C | 1 | 2 | 3 | 3 | 3 | 3 | - | - | - | - |
| 10 | CCGGCTGATTGCTCTAATGT | CAACATATGCCTCCACCACA | 816 | 58.4 | 5 | 104661 | 105738 | C | C | 1 | 2 | - | 2 | 2 | 2 | - | - | - | - |
| 11 | TGAAACAAAACGCTTTCTCG | TCAAAATAGTCACCAATCGGAGT | 988 | 56.8 | 5 | 3281961 | 3283550 | C | C | 1 | 2 | - | 1 | 1 | 1 | - | - | - | - |
| 13 | CAATGCAAGCCTCACGTATG | CTTATTGGCCATGCCTGACT | 647 | 58.4 | 5 | 22026785 | 22027585 | C | C | 1 | 2 | - | - | - | - | - | - | - | - |
| 12 | CGCAAAAGTGTACAAAATCTCAA | TGGAGTAGACCTGGCGGTAA | 644 | 59 | 5 | 2018577 | 2019377 | C | C | 1 | 2 | - | - | - | - | - | - | - | - |
| 14 | GGCACAACCAAGCCAATAAT | TTACACGCACCGAATTTGAC | 735 | 56.4 | 6 | 22061648 | 22062736 | C | C | 1 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
| 15 | AAACGGCAATTCGTCTTTTC | TTGCCTCGTAGCACTTTTCTC | 755 | 56.85 | 6 | 18749148 | 18750231 | C | C | 1 | 2 | - | 3 | 2 | 2 | 2 | 2 | 2 | 2 |
| 16 | AAAGAAAGCTTTGGCTTAGCTG | ACCCATATCACCCGACCATA | 710 | 58.4 | 6 | 23123270 | 23124363 | C | C | 1 | 2 | - | 3 | 3 | 1 | 2 | 2 | 2 | 2 |
| 17 | GAAGAAGCGAGCGAGAAGAA | CTTGCCTTCTGATCCCAATC | 910 | 58.4 | 7 | 22424472 | 22426064 | C | C | 1 | 2 | - | 3 | 1 | 1 | 2 | 2 | 2 | 2 |
| 18 | ATGTCGCAACTGAACCAAAA | CAAATTACATTCGGGGCCTA | 723 | 55.35 | 8 | 3233906 | 3235467 | C | C | 1 | 2 | 2 | 3 | 3 | 2 | - | - | - | - |
| 19 | CCAGCTCACCACTTCACAAA | CAAAACAATCGGTTGGGAAT | 712 | 56.35 | 8 | 16701066 | 16702155 | C | C | 1 | 2 | 2 | 2 | 2 | 1 | - | - | - | - |
| 20 | TGTACGTACGTGAGAATGAGATAAT | ACCCTCATGATGCATGGTTT | 726 | 58.65 | 8 | 2388601 | 2389689 | C | C | 1 | - | - | - | - | - | 2 | - | - | 2 |
| 21 | ATAATAGGCGGCAAGAGCAC | AAACCATCGAAATGCTCACC | 705 | 57.4 | 9 | 3996150 | 3997235 | C | C | 3 | 2 | 2 | 3 | 3 | 2 | - | - | - | - |
| 22 | CGATGGTACATCAAAAACAAACA | CCATATGGTCCAAGGAAGGA | 824 | 57.95 | 9 | 23729398 | 23730487 | C | C | 1 | 2 | 3 | 3 | 1 | 2 | 2 | 2 | 2 | 2 |
| 23 | AATTGGGACGAAAAGGGATT | CTTTCGGAAACAGAGGGTGT | 768 | 56.35 | 9 | 22776 | 23864 | C | C | 1 | 2 | - | 2 | 2 | 2 | - | - | - | - |
| 24 | AGCCTACCGCTTAATGCAAA | TGTACAATGTATTTTCCTAACCAAAG | 778 | 58.2 | 9 | 6049964 | 6051065 | C | C | 1 | 2 | - | 1 | 1 | 1 | - | - | - | - |
| 25 | ACAACGCACTTTCAAAAGCA | CACCGAAGTTTTCTTTTGCTG | 814 | 55.85 | 9 | 6435580 | 6436680 | C | C | 1 | 2 | - | - | - | - | - | - | - | - |
| 26 | TGAGAAGCGTTTTCTGAGCA | CGGGTGTTTTTATAAGTTACACGTT | 827 | 58.65 | 10 | 15070338 | 15071427 | C | C | 1 | 2 | 1 | 3 | 1 | 1 | 2 | 2 | 2 | 2 |
| 27 | CTCACCAGCAGGGACACATA | TGGGCCACATTTTCTTAGGT | 805 | 58.45 | 10 | 15382535 | 15383623 | C | C | 1 | 2 | - | 3 | 3 | 2 | 2 | 2 | 2 | 2 |
| 28 | TGTTTACGGCAAGAACAAGA | GGTGATCATGAAAGATGCAA | 842 | 54.3 | 3 | 12382669 | 12383669 | K | K | 2 | 3 | - | - | - | - | 1 | 1 | 1 | 1 |
| 29 | CACCTCCTTCTCGCAGTATT | GAGGAAGGAAAAGGTTCGAG | 897 | 58.4 | 5 | 3096661 | 3097721 | K | K | 2 | 1 | - | - | - | - | - | - | - | - |
| 30 | TTGGATCAGATTCGGTTTTT | ACGGCCAAAGATTACAACAT | 795 | 53.3 | 5 | 4793442 | 4794518 | K | K | 2 | 3 | 1 | 1 | 1 | 1 | - | - | - | - |
| 31 | CGAAACAAGAACCCAAAAAC | GCCCAATGACCACTCTAAAC | 883 | 56.35 | 5 | 19979539 | 19980595 | K | K | 2 | 3 | - | - | - | - | - | - | - | - |
| 32 | CCTTTGTGGGGTTTACTGTC | TCTGATTACCAAACCTTGCAT | 843 | 56.95 | 6 | 17041904 | 17042957 | K | K | 2 | 1 | - | - | - | - | 2 | 2 | 2 | 2 |
| 33 | GGTTTCCTTTGGTGGTGATA | AATAACCGGATCAAACCTGA | 784 | 55.35 | 6 | 24368107 | 24369107 | K | K | 2 | 3 | - | - | - | - | 1 | 1 | 1 | 1 |
| 34 | TGGTTGGAGATGGAAAATAAA | TCGAAATTCAGCTCAATCAA | 808 | 52.9 | 9 | 27626655 | 27627536 | K | K | 2 | 1 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
| 35 | GTGTAGCCTATGGGGACGAA | CGCCCCTAAAGACAGCTAAA | 701 | 59 | 1 | 963071 | 964133 | C | Shared | 1 | - | 1 | 1 | - | - | - | - | - | - |
| 36 | GCTGTCCCTGAAAAAGGAGA | TCCGGTTGGCTTAAAAATTG | 843 | 56.35 | 1 | 13502760 | 13503861 | C | Shared | 3 | 3 | 3 | 3 | 3 | 3 | 1 | 1 | 1 | 1 |
| 37 | AGCTCATACACCTCGGGAGA | ATGCAGCTCGTGTCTGAGAA | 759 | 59.45 | 1 | 19445593 | 19446681 | C | Shared | 1 | 1 | - | 1 | 1 | 1 | 2 | 2 | 2 | 2 |
| 38 | AGGTACGGTTTCTCGGATCA | CGTGCATAGCTGTAAAACGA | 620 | 57.4 | 1 | 2584681 | 2585481 | C | Shared | 3 | 3 | - | - | - | - | - | - | - | - |
| 39 | ACAGAGGACCATACCGGAAC | AAGTCCTAAATACTCCCTCCGTTT | 694 | 61.15 | 1 | 2961011 | 2961811 | C | Shared | 1 | 1 | - | - | - | - | - | - | - | - |
| 40 | TTCACCACGAGTTGTCTTCG | GCGTTTCTCAATTCCTCTGC | 611 | 58.4 | 1 | 9276641 | 9277441 | C | Shared | 1 | 1 | - | - | - | - | - | - | - | - |
| 41 | TTGCATTAGCCGACAATGAT | GGAGCTTCTTCTTTCCACCA | 630 | 56.35 | 1 | 10697577 | 10698377 | C | Shared | 1 | 1 | - | - | - | - | 2 | 2 | 2 | 2 |
| 42 | TGGGAATCGTAGGAATGGAG | CCATCAGAGTCTCACCGACA | 619 | 59.45 | 1 | 14754268 | 14755068 | C | Shared | 1 | 1 | - | - | - | - | 1 | 1 | 1 | 1 |
| 43 | TCAAGCAACTTCTCCAGCAA | AGGTCAGTGCAAGCAAAGGT | 432 | 57.4 | 1 | 18275269 | 18276069 | C | Shared | 1 | 1 | - | - | - | - | 1 | 1 | 1 | 1 |
| 44 | ATCCGATCAACATTGCCTTC | CATTTTGTGGTGAAGCTGGA | 652 | 56.4 | 1 | 22118044 | 22118844 | C | Shared | 1 | 1 | - | - | - | - | 2 | 2 | 2 | 2 |
| 45 | GAAGCCACTACTGGTGTGTATGA | TGACATCATTCTTGCTATGATCC | 661 | 61.1 | 1 | 23625986 | 23626786 | C | Shared | 1 | 1 | - | - | - | - | - | - | - | - |
| 46 | GCAATTGTCAACAATACGTAAGC | TGTCGTTTTCGGTTTTCTATG | 659 | 57.4 | 1 | 27587965 | 27588765 | C | Shared | 3 | 1 | - | - | - | - | - | - | - | - |
| 47 | TTGGGGACCAATACCAATGT | GAGTGTTGGCCTTCGTCTTC | 857 | 58.45 | 2 | 8839647 | 8841236 | C | Shared | 1 | 1 | 1 | 1 | 1 | 1 | 2 | 2 | 2 | 2 |
| 48 | AAAAGCCTAAGGGCATCTCC | AATGCCTGCCCGTTACTCTA | 856 | 58.4 | 2 | 20825514 | 20826587 | C | Shared | 1 | 1 | 1 | 1 | 1 | 1 | 2 | 2 | 2 | 2 |
| 49 | TGGTCTGATTGGTTCATTGG | CTGCAAAATAACCGGTTTGA | 719 | 55.35 | 2 | 532895 | 533984 | C | Shared | 1 | 1 | - | 1 | 1 | 1 | 2 | 2 | 2 | 2 |
| 50 | GCTGTTGATATCGAAGAATGTGA | AAAACCGGAAGGAGTAACAAAA | 707 | 57.95 | 2 | 6905529 | 6906618 | C | Shared | 1 | 1 | - | 1 | - | 1 | - | - | - | - |
| 51 | CCGTAGAATGTGTGGGTGAA | AGAAGGCAAAGGCAAAGACA | 809 | 57.4 | 2 | 25921691 | 25922779 | C | Shared | 3 | 3 | - | 3 | 3 | 2 | - | - | - | - |
| 52 | CAAAGCCAGCTTCGTCTTTC | TTTTGGAAACGAGGGAGTACA | 831 | 57.9 | 2 | 27426840 | 27427899 | C | Shared | 1 | 1 | - | 1 | 1 | 1 | - | - | - | - |
| 53 | CCAAGGGTGTTAGGGATATTT | CCCATACCTTTTCAAACCAG | 812 | 56.9 | 2 | 7699471 | 7700522 | K | Shared | 1 | 1 | - | - | - | - | - | - | - | - |
| 54 | CAGGTTGTTGTGGGTTTTGA | ACAGTCGCCATTTCTCACCT | 705 | 57.4 | 3 | 2817737 | 2818831 | C | Shared | 1 | 1 | 1 | 1 | 1 | 1 | - | - | - | - |
| 55 | AACGTGTGTGGGTGAAAGTG | TGTGTACATGGCATTTGCTG | 886 | 57.4 | 3 | 24785163 | 24786251 | C | Shared | 1 | 1 | 2 | 2 | 2 | 2 | - | - | - | - |
| 56 | CCCGATAAAAATTTATGGTAGCAC | ACGCAAGTCAGAGCTGGTTA | 876 | 59.25 | 3 | 29733660 | 29734749 | C | Shared | 1 | 1 | 1 | 1 | 1 | 1 | - | - | - | - |
| 57 | TGCTGCAAATGCAACTTTTT | CCTGCCCCAACTGTATTTTC | 934 | 55.35 | 3 | 22824441 | 22825982 | C | Shared | 1 | 1 | - | 1 | - | - | - | - | - | - |
| 58 | CGAATATGGACACGTGAAAA | GTCCATAGAGGCATCCAAAC | 778 | 56.35 | 3 | 8150869 | 8151901 | K | Shared | 3 | 3 | - | - | - | - | 2 | 2 | 2 | 2 |
| 59 | AAATGTCGCCACTGAATCTG | AACCGAATCAAACCAACCAG | 869 | 56.4 | 4 | 15959699 | 15960723 | C | Shared | 1 | 1 | 1 | 1 | 1 | 1 | 2 | 2 | 2 | 2 |
| 60 | TGAATTGAAGCCACAAGCTA | CACGTGTTGTTTTGTTCGTT | 842 | 54.3 | 4 | 13346608 | 13347631 | K | Shared | 1 | 1 | - | - | - | - | 1 | 1 | 1 | 1 |
| 61 | TGTCGTTTTGGTTTTCAATG | GTGCCAGATTTTTAGCGACT | 802 | 54.3 | 4 | 15212718 | 15213750 | K | Shared | 3 | 3 | - | - | - | - | 1 | 1 | 1 | 1 |
| 62 | AGCAAGTGCCTCTCGAGTCT | TCAAAATAGTCACCAATCGGAGT | 851 | 59.9 | 5 | 3281461 | 3283050 | C | Shared | 1 | 1 | 1 | 1 | 1 | 2 | - | - | - | - |
| 63 | TTACGGAGGGAAAGCAGAGA | CGTAAATGCTCTCCAAATGC | 776 | 57.4 | 5 | 10244950 | 10246022 | C | Shared | 1 | 1 | 3 | 3 | 3 | 1 | - | - | - | - |
| 64 | TCGATTTCTTCCCATCAACC | TTGGAAGTAGCTCCGCAAAT | 883 | 56.4 | 5 | 12834818 | 12835901 | C | Shared | 3 | 3 | 3 | 3 | 3 | 3 | 2 | 2 | 2 | 2 |
| 65 | CTCTTCCGCTCTACCAACTGA | TCCTTCAACCTCCAACATGA | 891 | 58.85 | 5 | 18108358 | 18109422 | C | Shared | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 66 | CTGCTTGAATCGGCTACAAA | CGGGCATCCAAATACTCTGT | 826 | 57.4 | 5 | 18163408 | 18164496 | C | Shared | 1 | 1 | 1 | 1 | 1 | 1 | 3 | 2 | 2 | 3 |
| 67 | GGAATGGTGAAGGACCTGAA | CCTAGCTCGACCATGGAGAC | 786 | 60.45 | 5 | 19371747 | 19372834 | C | Shared | 1 | 1 | 1 | 1 | 1 | 1 | - | - | - | - |
| 68 | TTTGCACCTAATTGATTTCCTTT | TGTCACGTGTGAAACATACTCC | 811 | 58 | 5 | 21905619 | 21906708 | C | Shared | 1 | 1 | 1 | 1 | 1 | 1 | - | - | - | - |
| 69 | GGGTGGTTAACGAGCCAGTA | TGGAAAACCATGGCAAAAA | 879 | 55.7 | 5 | 23188047 | 23189647 | C | Shared | 1 | 1 | 1 | 1 | 1 | 1 | 2 | 2 | 3 | 2 |
| 70 | GCGTGGTTACCTTCAATTCC | AGACTCGAGAGGCACTTGCT | 614 | 59.45 | 5 | 3282051 | 3282851 | C | Shared | 1 | 1 | - | - | - | - | 1 | 1 | 1 | 1 |
| 71 | TTTTTGGAGATGCATTTAGTGG | ACGCCAAAACTGAAAAGGAA | 465 | 55.45 | 5 | 7674505 | 7675305 | C | Shared | 1 | 1 | - | - | - | - | 1 | 1 | 1 | 1 |
| 72 | GGAGTTGCCATATTGGAAGG | GCCTCATACAGGAGGTGAGC | 683 | 60.45 | 5 | 12835307 | 12836107 | C | Shared | 1 | 1 | - | - | - | - | 1 | 1 | 1 | 1 |
| 74 | CAAAATCCACCGTCAAACTG | CCATTCAACCCGCTGTTACT | 454 | 57.4 | 5 | 16754371 | 16755171 | C | Shared | 2 | 3 | - | - | - | - | 3 | 3 | 3 | 3 |
| 75 | CGTGCATAGCTGTAAAACGAC | TGCATCTGCTGCTTTCATTT | 622 | 56.85 | 5 | 18109146 | 18109946 | C | Shared | 2 | 3 | - | - | - | - | - | - | - | - |
| 73 | AGGCCAACACAATAGGATCG | AAACGGCTACCACATCCAAG | 442 | 58.4 | 5 | 13116126 | 13116926 | C | Shared | 1 | 1 | - | - | - | - | 1 | 1 | 1 | 1 |
| 76 | CACGGTTGTGTGACAGATTG | GCCTAGGCTAGTGACCTCCA | 713 | 60.45 | 6 | 18132269 | 18133370 | C | Shared | 1 | 1 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
| 77 | ACACTGTGCGGACAAAAATG | TCTTTCTGCAAACCCCTAGC | 841 | 57.4 | 6 | 22195497 | 22196585 | C | Shared | 1 | 1 | 3 | 3 | 1 | 2 | - | - | - | - |
| 78 | TAAGGTGGGCCGTAACGTAG | GTCTCCGATGAAACGATGCT | 845 | 59.45 | 6 | 15006054 | 15007142 | C | Shared | 1 | 1 | - | 3 | 2 | 1 | - | - | - | - |
| 79 | TTGGGATGACAAGGATTTCT | CGACAAGCACAGAGACAAAG | 885 | 56.35 | 6 | 2249171 | 2250222 | K | Shared | 1 | 1 | - | - | - | - | - | - | - | - |
| 80 | CACATGGAACCTTTCTCCTC | TATCGGGTAAAGCCAATGAT | 774 | 56.35 | 6 | 20148620 | 20149708 | K | Shared | 1 | 1 | - | - | - | - | 1 | 1 | 1 | 1 |
| 81 | GGGGTTAGAATCGTCCTTTT | TTCTTGCGTGTTGGTATCAC | 858 | 56.4 | 6 | 21234008 | 21235039 | K | Shared | 1 | 3 | - | - | - | - | 2 | 2 | 2 | 2 |
| 82 | TGTAGACTCCTCCCAACGTCT | GGAAGTGGTGGATGCTGTTT | 810 | 59.85 | 8 | 13609744 | 13610827 | C | Shared | 1 | 1 | 1 | 3 | 3 | 1 | - | 2 | - | - |
| 83 | GGCAGAGAGCAGTTTCGATT | CTTCTCTGCCCAAACCTACC | 897 | 59.45 | 8 | 17589879 | 17591468 | C | Shared | 1 | 1 | 2 | 3 | 1 | 2 | - | - | - | - |
| 84 | TTGAAAAGCAAACCCTTCTC | ATTTTGGTTGGTTCATACCG | 779 | 54.3 | 8 | 19318537 | 19319537 | K | Shared | 1 | 1 | - | - | - | - | - | - | - | - |
| 85 | GCACTGAGCTTTGTCATGGA | TCTCACGTCCCTCTCCATCT | 742 | 59.45 | 9 | 6120652 | 6121741 | C | Shared | 1 | - | - | - | - | - | 3 | 2 | 3 | 3 |
| 86 | CGAGGAATGTGGTGATGATG | CGAGGAATGTGGTGATGATG | 810 | 58.4 | 9 | 6223231 | 6224320 | C | Shared | 1 | 1 | - | - | - | - | - | - | - | - |
| 87 | AGCAGCTATTGCATGGTCAC | TTGAGCTCTATTGGCAAGCA | 722 | 57.4 | 9 | 19954499 | 19955588 | C | Shared | 1 | 1 | 1 | 1 | 1 | 1 | 2 | 2 | 2 | 2 |
| 88 | CCACCCTTCAAGCATCAAAT | AAACAGAGACAACGCTGCTG | 876 | 57.4 | 9 | 26437989 | 26439077 | C | Shared | 1 | 1 | 3 | 3 | 1 | 2 | 3 | 1 | 3 | 2 |
| 89 | GGTTTGCTACCCACAAAATCA | CGCTCCTCTATTCGGACACT | 898 | 58.95 | 9 | 26805934 | 26807535 | C | Shared | 1 | 1 | 1 | 1 | 1 | 2 | - | - | - | - |
| 90 | AGGCCCCAATTTCCCTATAA | CCTTTTTCACCATTTACATTCG | 877 | 56.5 | 10 | 7137934 | 7139011 | C | Shared | 1 | 1 | 1 | 3 | 3 | 1 | - | - | - | - |
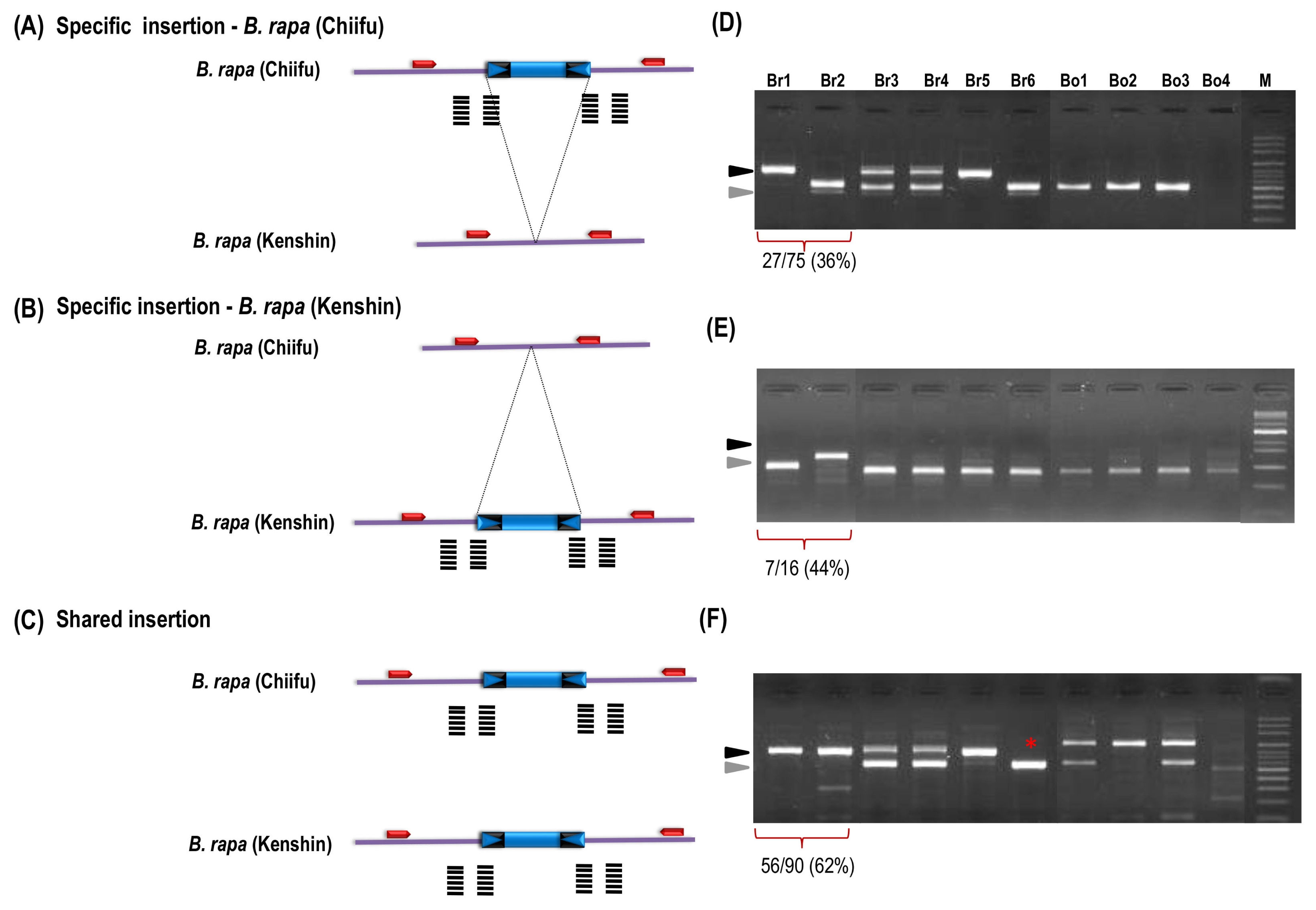
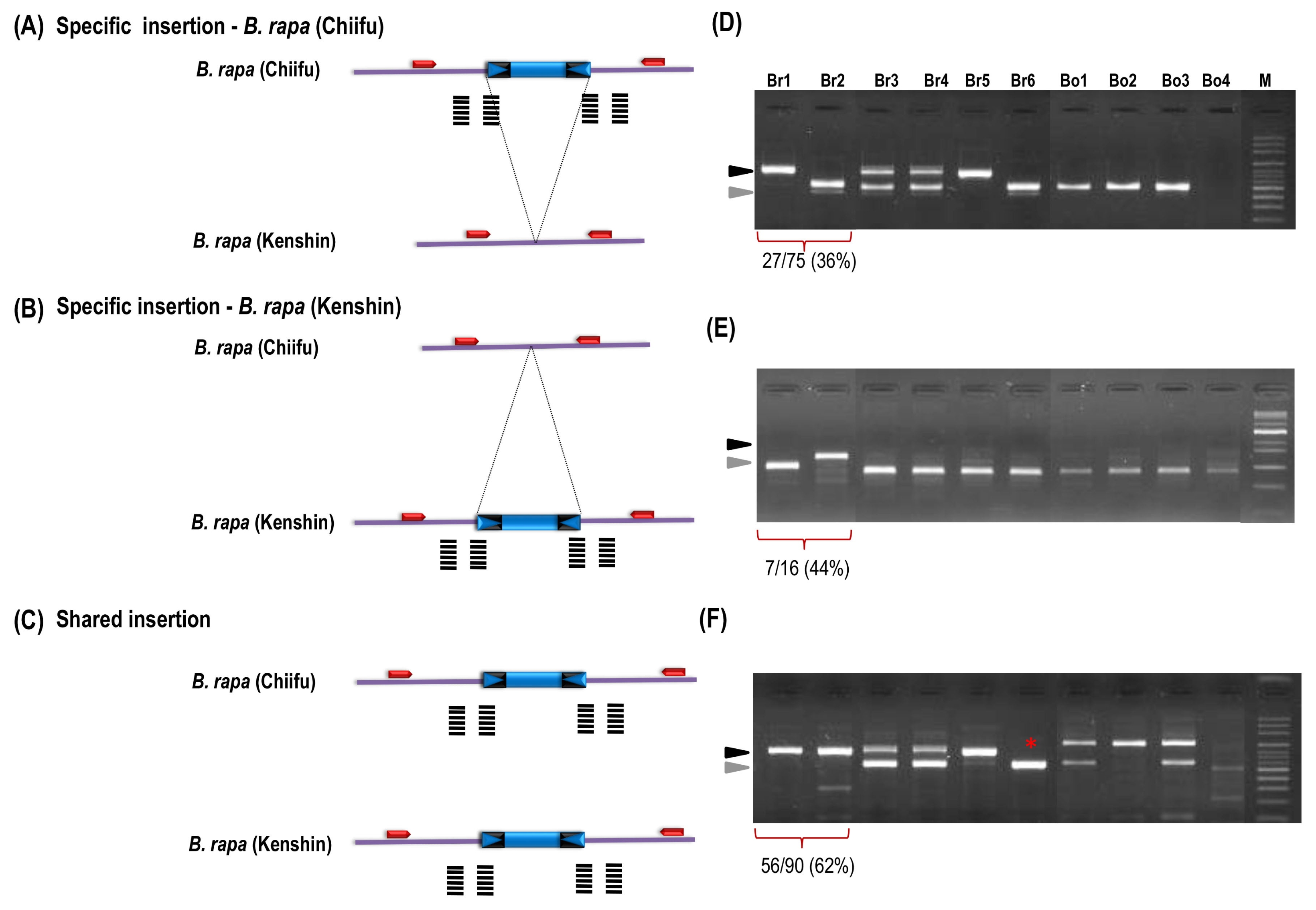
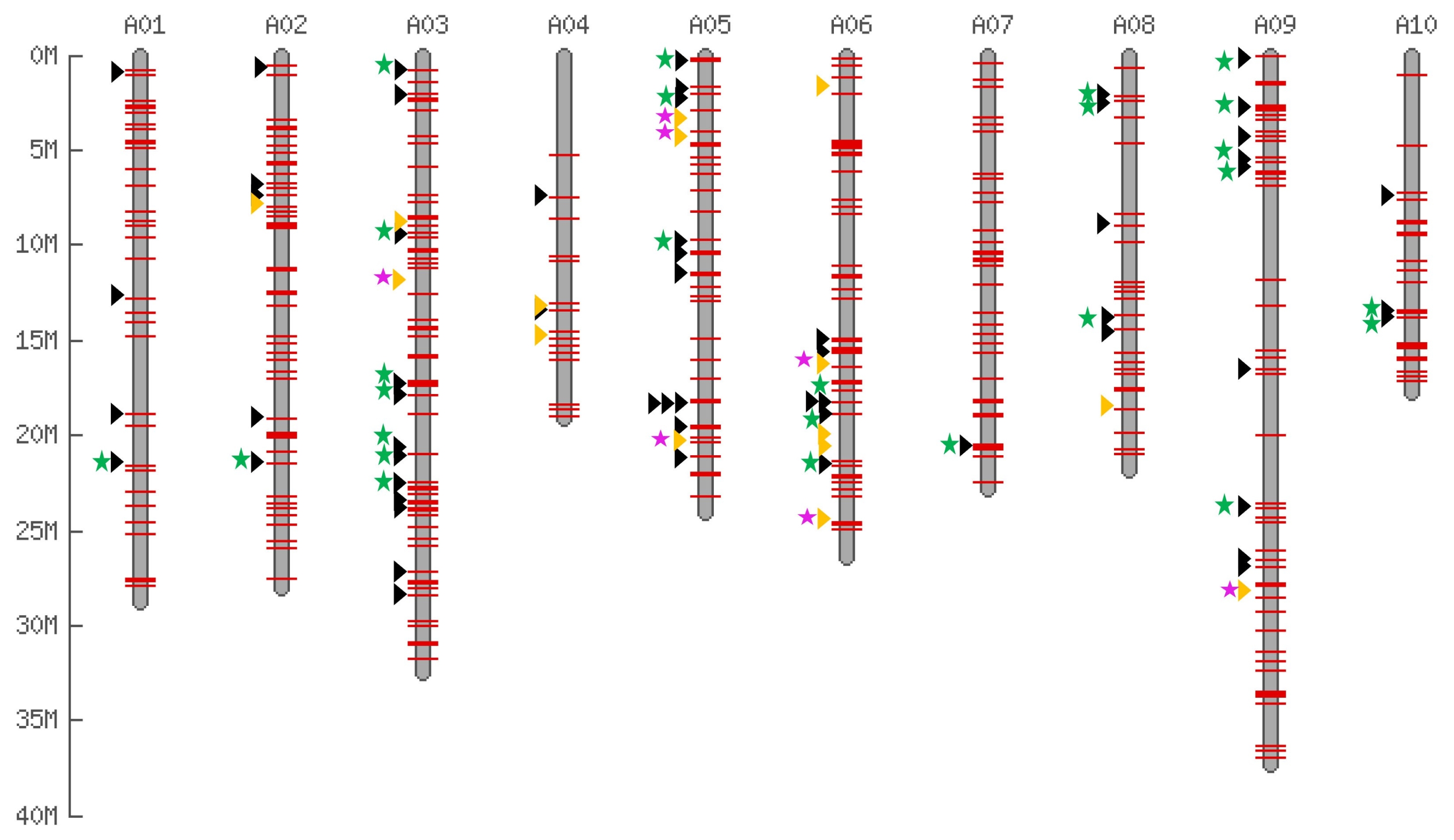
z)Scores of gel profile were followed by previous report (Murukarthick et al. 2014) as 1, full site; 2, empty site; 3, full and empty site; and -, no amplification. Bold used as a representative for each group in Fig. 3.
Bs2: BraSto-2, Chr#: chromosome numbers, NGS: next-generation sequencing, PCR: polymerase chain reaction, C: ‘Chiifu’, K: ‘Kenshin’.
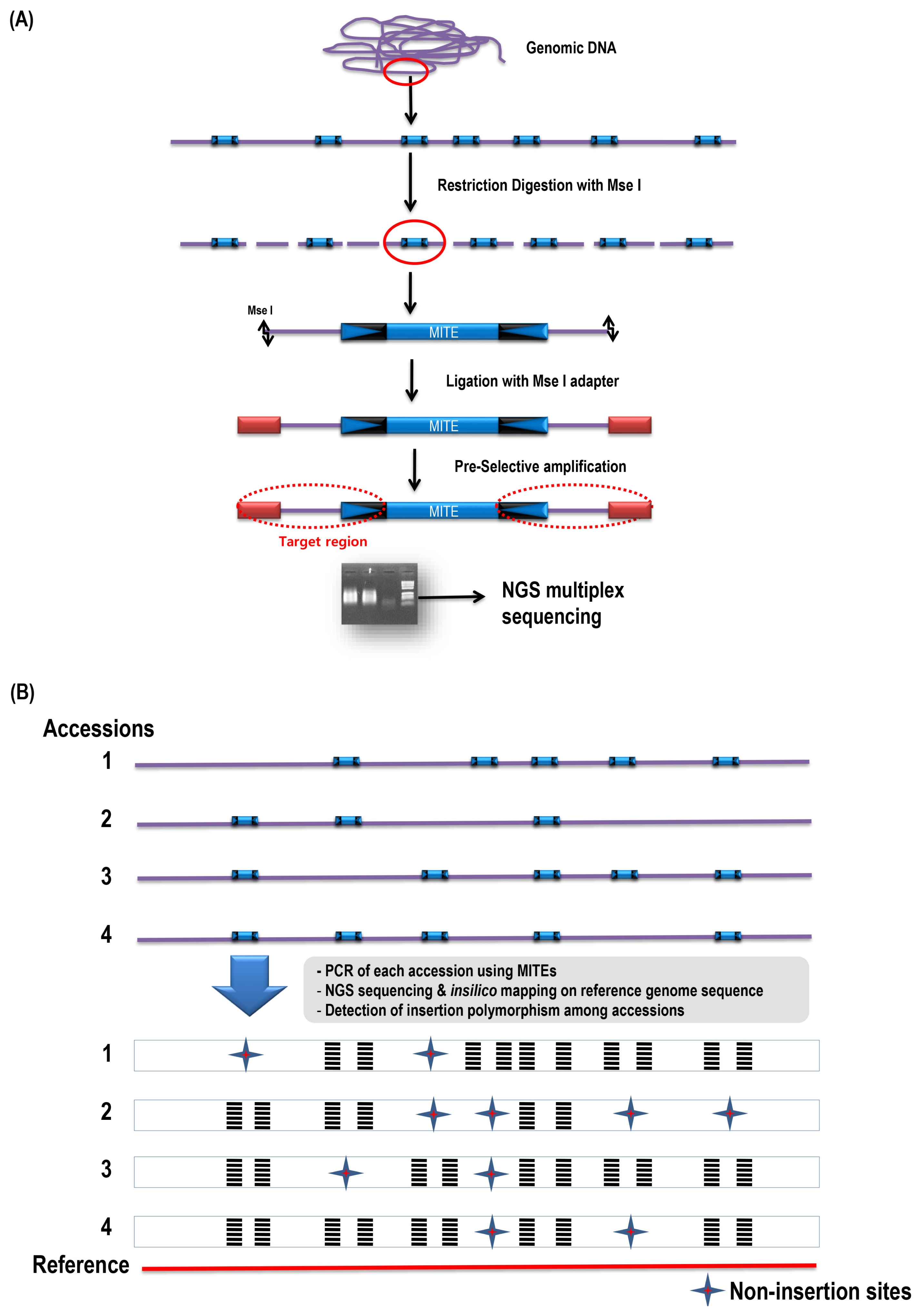

List of accessions used for the display and insertion survey.
| No. | ID | Species | Accession no. | Reference |
|---|---|---|---|---|
| 1 | Br1 | Brassica rapa | ‘Chiifu’ (C) | ( |
| 2 | Br2 | B. rapa | ‘Kenshin’ (K) | ( |
| 3 | Br3 | B. rapa | OC 1 | ( |
| 4 | Br4 | B. rapa | OC 2 | ( |
| 5 | Br5 | B. rapa | YE 1 | ( |
| 6 | Br6 | B. rapa | YE 2 | ( |
| 7 | Bo1 | Brassica oleracea | C1234 | ( |
| 8 | Bo2 | B. oleracea | C1184 | ( |
| 9 | Bo3 | B. oleracea | C1235 | ( |
| 10 | Bo4 | B. oleracea | C1176 | ( |
Summary of reads analysis from NGS-based transposon display of Bs2 MITE family against two Brassica rapa accessions.
| Accession | Insertion sites based on in silico mapping | PCR validation | |||
|---|---|---|---|---|---|
|
|
| ||||
| Total | Accession specificz) | Success | IP-Bs2 among Br1, Br2 | IP-Bs2 among 10 accessions | |
| Br1 | 127 | 83 | 75 | 27 (36) | 59 (78) |
| Br2 | 60 | 16 | 15 | 7 (46) | 10 (66) |
Values are presented as number only or number (%).
z)Bs-2 sites specific to Br1 and Br2.
NGS: next-generation sequencing, MITE: miniature inverted-repeat transposable element, PCR: polymerase chain reaction, IP-Bs2: Insertion polymorphism of Brasto-2 (bs2) members.
Insertion polymorphisms survey of Bs2 candidates based on NGS-based transposon display analysis against 10 Brassica accessions.
| No. | Primer sequence | Product size (bp) | Temperature (°C) | Primer source | In silico specificity | PCR validation | Gel profilez) | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
|
|
| |||||||||||||||||
| Forward (5′–3′) | Reverse (5′–3′) | Chr# | Start | End | Br1 | Br2 | Br3 | Br 4 | Br 5 | Br 6 | Bo1 | Bo2 | Bo3 | Bo4 | |||||
| 1 | TTGTTTGATCAGGGGAGCAT | CCAGGGTACCTATCCGCTTT | 858 | 58.45 | 1 | 21801279 | 21802374 | C | C | 1 | 2 | - | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
| 2 | TTGCAGATTTGATGTTGTGAA | GCGCGGGTTATTACCTAGTG | 713 | 57 | 2 | 23504716 | 23506305 | C | C | 1 | 2 | 3 | 1 | 3 | 1 | 1 | 1 | 1 | 1 |
| 3 | CTACCGCCAAGTTCAAGCA | TAAGGGACCCCAAAGCATAA | 773 | 56.85 | 3 | 742954 | 744043 | C | C | 1 | 2 | 3 | 3 | 3 | 3 | 1 | 1 | 1 | 1 |
| 4 | TTGAGCCTAGTCCGAGCAAT | CTCATCTCCAAACCCCATTC | 749 | 58.4 | 3 | 10933621 | 10934710 | C | C | 1 | 2 | 1 | 3 | 3 | 1 | 1 | 1 | 1 | 1 |
| 5 | ACCGTGGTGAGGTAAAAGGA | TGTTCTTTGCCTTGGAACCT | 751 | 57.4 | 3 | 18816045 | 18817634 | C | C | 1 | 2 | 1 | 3 | 3 | 1 | 2 | 2 | 2 | 2 |
| 6 | TGCAGATCTCTTTGCTCATCA | CTGTTCTCTGCGATGCTCAC | 746 | 58.95 | 3 | 20935930 | 20936992 | C | C | 1 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
| 7 | GCATCTCTGAGCTGGTTTCC | GTCCTCGTTGACGGAGAAAG | 976 | 60.5 | 3 | 17138648 | 17140237 | C | C | 1 | 2 | - | - | - | - | - | - | - | - |
| 8 | GCAAATTATGCACAATCTTACAA | TGGATATATGATGCTGTCAAAAA | 751 | 55.7 | 3 | 23886171 | 23887233 | C | C | 1 | 2 | - | 2 | 1 | 2 | - | - | - | - |
| 9 | GGAATCGAATGGGATCAAAA | TCTAAAAACGCTGGCTCCAT | 886 | 55.35 | 5 | 11493271 | 11494360 | C | C | 1 | 2 | 3 | 3 | 3 | 3 | - | - | - | - |
| 10 | CCGGCTGATTGCTCTAATGT | CAACATATGCCTCCACCACA | 816 | 58.4 | 5 | 104661 | 105738 | C | C | 1 | 2 | - | 2 | 2 | 2 | - | - | - | - |
| 11 | TGAAACAAAACGCTTTCTCG | TCAAAATAGTCACCAATCGGAGT | 988 | 56.8 | 5 | 3281961 | 3283550 | C | C | 1 | 2 | - | 1 | 1 | 1 | - | - | - | - |
| 13 | CAATGCAAGCCTCACGTATG | CTTATTGGCCATGCCTGACT | 647 | 58.4 | 5 | 22026785 | 22027585 | C | C | 1 | 2 | - | - | - | - | - | - | - | - |
| 12 | CGCAAAAGTGTACAAAATCTCAA | TGGAGTAGACCTGGCGGTAA | 644 | 59 | 5 | 2018577 | 2019377 | C | C | 1 | 2 | - | - | - | - | - | - | - | - |
| 14 | GGCACAACCAAGCCAATAAT | TTACACGCACCGAATTTGAC | 735 | 56.4 | 6 | 22061648 | 22062736 | C | C | 1 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
| 15 | AAACGGCAATTCGTCTTTTC | TTGCCTCGTAGCACTTTTCTC | 755 | 56.85 | 6 | 18749148 | 18750231 | C | C | 1 | 2 | - | 3 | 2 | 2 | 2 | 2 | 2 | 2 |
| 16 | AAAGAAAGCTTTGGCTTAGCTG | ACCCATATCACCCGACCATA | 710 | 58.4 | 6 | 23123270 | 23124363 | C | C | 1 | 2 | - | 3 | 3 | 1 | 2 | 2 | 2 | 2 |
| 17 | GAAGAAGCGAGCGAGAAGAA | CTTGCCTTCTGATCCCAATC | 910 | 58.4 | 7 | 22424472 | 22426064 | C | C | 1 | 2 | - | 3 | 1 | 1 | 2 | 2 | 2 | 2 |
| 18 | ATGTCGCAACTGAACCAAAA | CAAATTACATTCGGGGCCTA | 723 | 55.35 | 8 | 3233906 | 3235467 | C | C | 1 | 2 | 2 | 3 | 3 | 2 | - | - | - | - |
| 19 | CCAGCTCACCACTTCACAAA | CAAAACAATCGGTTGGGAAT | 712 | 56.35 | 8 | 16701066 | 16702155 | C | C | 1 | 2 | 2 | 2 | 2 | 1 | - | - | - | - |
| 20 | TGTACGTACGTGAGAATGAGATAAT | ACCCTCATGATGCATGGTTT | 726 | 58.65 | 8 | 2388601 | 2389689 | C | C | 1 | - | - | - | - | - | 2 | - | - | 2 |
| 21 | ATAATAGGCGGCAAGAGCAC | AAACCATCGAAATGCTCACC | 705 | 57.4 | 9 | 3996150 | 3997235 | C | C | 3 | 2 | 2 | 3 | 3 | 2 | - | - | - | - |
| 22 | CGATGGTACATCAAAAACAAACA | CCATATGGTCCAAGGAAGGA | 824 | 57.95 | 9 | 23729398 | 23730487 | C | C | 1 | 2 | 3 | 3 | 1 | 2 | 2 | 2 | 2 | 2 |
| 23 | AATTGGGACGAAAAGGGATT | CTTTCGGAAACAGAGGGTGT | 768 | 56.35 | 9 | 22776 | 23864 | C | C | 1 | 2 | - | 2 | 2 | 2 | - | - | - | - |
| 24 | AGCCTACCGCTTAATGCAAA | TGTACAATGTATTTTCCTAACCAAAG | 778 | 58.2 | 9 | 6049964 | 6051065 | C | C | 1 | 2 | - | 1 | 1 | 1 | - | - | - | - |
| 25 | ACAACGCACTTTCAAAAGCA | CACCGAAGTTTTCTTTTGCTG | 814 | 55.85 | 9 | 6435580 | 6436680 | C | C | 1 | 2 | - | - | - | - | - | - | - | - |
| 26 | TGAGAAGCGTTTTCTGAGCA | CGGGTGTTTTTATAAGTTACACGTT | 827 | 58.65 | 10 | 15070338 | 15071427 | C | C | 1 | 2 | 1 | 3 | 1 | 1 | 2 | 2 | 2 | 2 |
| 27 | CTCACCAGCAGGGACACATA | TGGGCCACATTTTCTTAGGT | 805 | 58.45 | 10 | 15382535 | 15383623 | C | C | 1 | 2 | - | 3 | 3 | 2 | 2 | 2 | 2 | 2 |
| 28 | TGTTTACGGCAAGAACAAGA | GGTGATCATGAAAGATGCAA | 842 | 54.3 | 3 | 12382669 | 12383669 | K | K | 2 | 3 | - | - | - | - | 1 | 1 | 1 | 1 |
| 29 | CACCTCCTTCTCGCAGTATT | GAGGAAGGAAAAGGTTCGAG | 897 | 58.4 | 5 | 3096661 | 3097721 | K | K | 2 | 1 | - | - | - | - | - | - | - | - |
| 30 | TTGGATCAGATTCGGTTTTT | ACGGCCAAAGATTACAACAT | 795 | 53.3 | 5 | 4793442 | 4794518 | K | K | 2 | 3 | 1 | 1 | 1 | 1 | - | - | - | - |
| 31 | CGAAACAAGAACCCAAAAAC | GCCCAATGACCACTCTAAAC | 883 | 56.35 | 5 | 19979539 | 19980595 | K | K | 2 | 3 | - | - | - | - | - | - | - | - |
| 32 | CCTTTGTGGGGTTTACTGTC | TCTGATTACCAAACCTTGCAT | 843 | 56.95 | 6 | 17041904 | 17042957 | K | K | 2 | 1 | - | - | - | - | 2 | 2 | 2 | 2 |
| 33 | GGTTTCCTTTGGTGGTGATA | AATAACCGGATCAAACCTGA | 784 | 55.35 | 6 | 24368107 | 24369107 | K | K | 2 | 3 | - | - | - | - | 1 | 1 | 1 | 1 |
| 34 | TGGTTGGAGATGGAAAATAAA | TCGAAATTCAGCTCAATCAA | 808 | 52.9 | 9 | 27626655 | 27627536 | K | K | 2 | 1 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
| 35 | GTGTAGCCTATGGGGACGAA | CGCCCCTAAAGACAGCTAAA | 701 | 59 | 1 | 963071 | 964133 | C | Shared | 1 | - | 1 | 1 | - | - | - | - | - | - |
| 36 | GCTGTCCCTGAAAAAGGAGA | TCCGGTTGGCTTAAAAATTG | 843 | 56.35 | 1 | 13502760 | 13503861 | C | Shared | 3 | 3 | 3 | 3 | 3 | 3 | 1 | 1 | 1 | 1 |
| 37 | AGCTCATACACCTCGGGAGA | ATGCAGCTCGTGTCTGAGAA | 759 | 59.45 | 1 | 19445593 | 19446681 | C | Shared | 1 | 1 | - | 1 | 1 | 1 | 2 | 2 | 2 | 2 |
| 38 | AGGTACGGTTTCTCGGATCA | CGTGCATAGCTGTAAAACGA | 620 | 57.4 | 1 | 2584681 | 2585481 | C | Shared | 3 | 3 | - | - | - | - | - | - | - | - |
| 39 | ACAGAGGACCATACCGGAAC | AAGTCCTAAATACTCCCTCCGTTT | 694 | 61.15 | 1 | 2961011 | 2961811 | C | Shared | 1 | 1 | - | - | - | - | - | - | - | - |
| 40 | TTCACCACGAGTTGTCTTCG | GCGTTTCTCAATTCCTCTGC | 611 | 58.4 | 1 | 9276641 | 9277441 | C | Shared | 1 | 1 | - | - | - | - | - | - | - | - |
| 41 | TTGCATTAGCCGACAATGAT | GGAGCTTCTTCTTTCCACCA | 630 | 56.35 | 1 | 10697577 | 10698377 | C | Shared | 1 | 1 | - | - | - | - | 2 | 2 | 2 | 2 |
| 42 | TGGGAATCGTAGGAATGGAG | CCATCAGAGTCTCACCGACA | 619 | 59.45 | 1 | 14754268 | 14755068 | C | Shared | 1 | 1 | - | - | - | - | 1 | 1 | 1 | 1 |
| 43 | TCAAGCAACTTCTCCAGCAA | AGGTCAGTGCAAGCAAAGGT | 432 | 57.4 | 1 | 18275269 | 18276069 | C | Shared | 1 | 1 | - | - | - | - | 1 | 1 | 1 | 1 |
| 44 | ATCCGATCAACATTGCCTTC | CATTTTGTGGTGAAGCTGGA | 652 | 56.4 | 1 | 22118044 | 22118844 | C | Shared | 1 | 1 | - | - | - | - | 2 | 2 | 2 | 2 |
| 45 | GAAGCCACTACTGGTGTGTATGA | TGACATCATTCTTGCTATGATCC | 661 | 61.1 | 1 | 23625986 | 23626786 | C | Shared | 1 | 1 | - | - | - | - | - | - | - | - |
| 46 | GCAATTGTCAACAATACGTAAGC | TGTCGTTTTCGGTTTTCTATG | 659 | 57.4 | 1 | 27587965 | 27588765 | C | Shared | 3 | 1 | - | - | - | - | - | - | - | - |
| 47 | TTGGGGACCAATACCAATGT | GAGTGTTGGCCTTCGTCTTC | 857 | 58.45 | 2 | 8839647 | 8841236 | C | Shared | 1 | 1 | 1 | 1 | 1 | 1 | 2 | 2 | 2 | 2 |
| 48 | AAAAGCCTAAGGGCATCTCC | AATGCCTGCCCGTTACTCTA | 856 | 58.4 | 2 | 20825514 | 20826587 | C | Shared | 1 | 1 | 1 | 1 | 1 | 1 | 2 | 2 | 2 | 2 |
| 49 | TGGTCTGATTGGTTCATTGG | CTGCAAAATAACCGGTTTGA | 719 | 55.35 | 2 | 532895 | 533984 | C | Shared | 1 | 1 | - | 1 | 1 | 1 | 2 | 2 | 2 | 2 |
| 50 | GCTGTTGATATCGAAGAATGTGA | AAAACCGGAAGGAGTAACAAAA | 707 | 57.95 | 2 | 6905529 | 6906618 | C | Shared | 1 | 1 | - | 1 | - | 1 | - | - | - | - |
| 51 | CCGTAGAATGTGTGGGTGAA | AGAAGGCAAAGGCAAAGACA | 809 | 57.4 | 2 | 25921691 | 25922779 | C | Shared | 3 | 3 | - | 3 | 3 | 2 | - | - | - | - |
| 52 | CAAAGCCAGCTTCGTCTTTC | TTTTGGAAACGAGGGAGTACA | 831 | 57.9 | 2 | 27426840 | 27427899 | C | Shared | 1 | 1 | - | 1 | 1 | 1 | - | - | - | - |
| 53 | CCAAGGGTGTTAGGGATATTT | CCCATACCTTTTCAAACCAG | 812 | 56.9 | 2 | 7699471 | 7700522 | K | Shared | 1 | 1 | - | - | - | - | - | - | - | - |
| 54 | CAGGTTGTTGTGGGTTTTGA | ACAGTCGCCATTTCTCACCT | 705 | 57.4 | 3 | 2817737 | 2818831 | C | Shared | 1 | 1 | 1 | 1 | 1 | 1 | - | - | - | - |
| 55 | AACGTGTGTGGGTGAAAGTG | TGTGTACATGGCATTTGCTG | 886 | 57.4 | 3 | 24785163 | 24786251 | C | Shared | 1 | 1 | 2 | 2 | 2 | 2 | - | - | - | - |
| 56 | CCCGATAAAAATTTATGGTAGCAC | ACGCAAGTCAGAGCTGGTTA | 876 | 59.25 | 3 | 29733660 | 29734749 | C | Shared | 1 | 1 | 1 | 1 | 1 | 1 | - | - | - | - |
| 57 | TGCTGCAAATGCAACTTTTT | CCTGCCCCAACTGTATTTTC | 934 | 55.35 | 3 | 22824441 | 22825982 | C | Shared | 1 | 1 | - | 1 | - | - | - | - | - | - |
| 58 | CGAATATGGACACGTGAAAA | GTCCATAGAGGCATCCAAAC | 778 | 56.35 | 3 | 8150869 | 8151901 | K | Shared | 3 | 3 | - | - | - | - | 2 | 2 | 2 | 2 |
| 59 | AAATGTCGCCACTGAATCTG | AACCGAATCAAACCAACCAG | 869 | 56.4 | 4 | 15959699 | 15960723 | C | Shared | 1 | 1 | 1 | 1 | 1 | 1 | 2 | 2 | 2 | 2 |
| 60 | TGAATTGAAGCCACAAGCTA | CACGTGTTGTTTTGTTCGTT | 842 | 54.3 | 4 | 13346608 | 13347631 | K | Shared | 1 | 1 | - | - | - | - | 1 | 1 | 1 | 1 |
| 61 | TGTCGTTTTGGTTTTCAATG | GTGCCAGATTTTTAGCGACT | 802 | 54.3 | 4 | 15212718 | 15213750 | K | Shared | 3 | 3 | - | - | - | - | 1 | 1 | 1 | 1 |
| 62 | AGCAAGTGCCTCTCGAGTCT | TCAAAATAGTCACCAATCGGAGT | 851 | 59.9 | 5 | 3281461 | 3283050 | C | Shared | 1 | 1 | 1 | 1 | 1 | 2 | - | - | - | - |
| 63 | TTACGGAGGGAAAGCAGAGA | CGTAAATGCTCTCCAAATGC | 776 | 57.4 | 5 | 10244950 | 10246022 | C | Shared | 1 | 1 | 3 | 3 | 3 | 1 | - | - | - | - |
| 64 | TCGATTTCTTCCCATCAACC | TTGGAAGTAGCTCCGCAAAT | 883 | 56.4 | 5 | 12834818 | 12835901 | C | Shared | 3 | 3 | 3 | 3 | 3 | 3 | 2 | 2 | 2 | 2 |
| 65 | CTCTTCCGCTCTACCAACTGA | TCCTTCAACCTCCAACATGA | 891 | 58.85 | 5 | 18108358 | 18109422 | C | Shared | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 66 | CTGCTTGAATCGGCTACAAA | CGGGCATCCAAATACTCTGT | 826 | 57.4 | 5 | 18163408 | 18164496 | C | Shared | 1 | 1 | 1 | 1 | 1 | 1 | 3 | 2 | 2 | 3 |
| 67 | GGAATGGTGAAGGACCTGAA | CCTAGCTCGACCATGGAGAC | 786 | 60.45 | 5 | 19371747 | 19372834 | C | Shared | 1 | 1 | 1 | 1 | 1 | 1 | - | - | - | - |
| 68 | TTTGCACCTAATTGATTTCCTTT | TGTCACGTGTGAAACATACTCC | 811 | 58 | 5 | 21905619 | 21906708 | C | Shared | 1 | 1 | 1 | 1 | 1 | 1 | - | - | - | - |
| 69 | GGGTGGTTAACGAGCCAGTA | TGGAAAACCATGGCAAAAA | 879 | 55.7 | 5 | 23188047 | 23189647 | C | Shared | 1 | 1 | 1 | 1 | 1 | 1 | 2 | 2 | 3 | 2 |
| 70 | GCGTGGTTACCTTCAATTCC | AGACTCGAGAGGCACTTGCT | 614 | 59.45 | 5 | 3282051 | 3282851 | C | Shared | 1 | 1 | - | - | - | - | 1 | 1 | 1 | 1 |
| 71 | TTTTTGGAGATGCATTTAGTGG | ACGCCAAAACTGAAAAGGAA | 465 | 55.45 | 5 | 7674505 | 7675305 | C | Shared | 1 | 1 | - | - | - | - | 1 | 1 | 1 | 1 |
| 72 | GGAGTTGCCATATTGGAAGG | GCCTCATACAGGAGGTGAGC | 683 | 60.45 | 5 | 12835307 | 12836107 | C | Shared | 1 | 1 | - | - | - | - | 1 | 1 | 1 | 1 |
| 74 | CAAAATCCACCGTCAAACTG | CCATTCAACCCGCTGTTACT | 454 | 57.4 | 5 | 16754371 | 16755171 | C | Shared | 2 | 3 | - | - | - | - | 3 | 3 | 3 | 3 |
| 75 | CGTGCATAGCTGTAAAACGAC | TGCATCTGCTGCTTTCATTT | 622 | 56.85 | 5 | 18109146 | 18109946 | C | Shared | 2 | 3 | - | - | - | - | - | - | - | - |
| 73 | AGGCCAACACAATAGGATCG | AAACGGCTACCACATCCAAG | 442 | 58.4 | 5 | 13116126 | 13116926 | C | Shared | 1 | 1 | - | - | - | - | 1 | 1 | 1 | 1 |
| 76 | CACGGTTGTGTGACAGATTG | GCCTAGGCTAGTGACCTCCA | 713 | 60.45 | 6 | 18132269 | 18133370 | C | Shared | 1 | 1 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
| 77 | ACACTGTGCGGACAAAAATG | TCTTTCTGCAAACCCCTAGC | 841 | 57.4 | 6 | 22195497 | 22196585 | C | Shared | 1 | 1 | 3 | 3 | 1 | 2 | - | - | - | - |
| 78 | TAAGGTGGGCCGTAACGTAG | GTCTCCGATGAAACGATGCT | 845 | 59.45 | 6 | 15006054 | 15007142 | C | Shared | 1 | 1 | - | 3 | 2 | 1 | - | - | - | - |
| 79 | TTGGGATGACAAGGATTTCT | CGACAAGCACAGAGACAAAG | 885 | 56.35 | 6 | 2249171 | 2250222 | K | Shared | 1 | 1 | - | - | - | - | - | - | - | - |
| 80 | CACATGGAACCTTTCTCCTC | TATCGGGTAAAGCCAATGAT | 774 | 56.35 | 6 | 20148620 | 20149708 | K | Shared | 1 | 1 | - | - | - | - | 1 | 1 | 1 | 1 |
| 81 | GGGGTTAGAATCGTCCTTTT | TTCTTGCGTGTTGGTATCAC | 858 | 56.4 | 6 | 21234008 | 21235039 | K | Shared | 1 | 3 | - | - | - | - | 2 | 2 | 2 | 2 |
| 82 | TGTAGACTCCTCCCAACGTCT | GGAAGTGGTGGATGCTGTTT | 810 | 59.85 | 8 | 13609744 | 13610827 | C | Shared | 1 | 1 | 1 | 3 | 3 | 1 | - | 2 | - | - |
| 83 | GGCAGAGAGCAGTTTCGATT | CTTCTCTGCCCAAACCTACC | 897 | 59.45 | 8 | 17589879 | 17591468 | C | Shared | 1 | 1 | 2 | 3 | 1 | 2 | - | - | - | - |
| 84 | TTGAAAAGCAAACCCTTCTC | ATTTTGGTTGGTTCATACCG | 779 | 54.3 | 8 | 19318537 | 19319537 | K | Shared | 1 | 1 | - | - | - | - | - | - | - | - |
| 85 | GCACTGAGCTTTGTCATGGA | TCTCACGTCCCTCTCCATCT | 742 | 59.45 | 9 | 6120652 | 6121741 | C | Shared | 1 | - | - | - | - | - | 3 | 2 | 3 | 3 |
| 86 | CGAGGAATGTGGTGATGATG | CGAGGAATGTGGTGATGATG | 810 | 58.4 | 9 | 6223231 | 6224320 | C | Shared | 1 | 1 | - | - | - | - | - | - | - | - |
| 87 | AGCAGCTATTGCATGGTCAC | TTGAGCTCTATTGGCAAGCA | 722 | 57.4 | 9 | 19954499 | 19955588 | C | Shared | 1 | 1 | 1 | 1 | 1 | 1 | 2 | 2 | 2 | 2 |
| 88 | CCACCCTTCAAGCATCAAAT | AAACAGAGACAACGCTGCTG | 876 | 57.4 | 9 | 26437989 | 26439077 | C | Shared | 1 | 1 | 3 | 3 | 1 | 2 | 3 | 1 | 3 | 2 |
| 89 | GGTTTGCTACCCACAAAATCA | CGCTCCTCTATTCGGACACT | 898 | 58.95 | 9 | 26805934 | 26807535 | C | Shared | 1 | 1 | 1 | 1 | 1 | 2 | - | - | - | - |
| 90 | AGGCCCCAATTTCCCTATAA | CCTTTTTCACCATTTACATTCG | 877 | 56.5 | 10 | 7137934 | 7139011 | C | Shared | 1 | 1 | 1 | 3 | 3 | 1 | - | - | - | - |
z)Scores of gel profile were followed by previous report (
Bs2: BraSto-2, Chr#: chromosome numbers, NGS: next-generation sequencing, PCR: polymerase chain reaction, C: ‘Chiifu’, K: ‘Kenshin’.
Values are presented as number only or number (%).
Bs-2 sites specific to Br1 and Br2.
NGS: next-generation sequencing, MITE: miniature inverted-repeat transposable element, PCR: polymerase chain reaction, IP-Bs2: Insertion polymorphism of Brasto-2 (bs2) members.
Scores of gel profile were followed by previous report (
Bs2: BraSto-2, Chr#: chromosome numbers, NGS: next-generation sequencing, PCR: polymerase chain reaction, C: ‘Chiifu’, K: ‘Kenshin’.
